
Rumor Echo Chamber: An Amplifier of Rumor Spread in Social Media
Daejin Choi, Selin Chun, Hyunchul Oh, Jinyoung Han, and Taekyoung “Ted” Kwon, Scientific Reports 10, 310 (2020)
Citation
Abstract
Spreading rumors on the Internet has become increasingly pervasive due to the proliferation of online social media. This paper investigates how rumors are amplified by a group of users who share similar interests or views, dubbed as an echo chamber. To this end, we identify and analyze rumor echo chambers, each of which is a group of users who have participated in propagating common rumors. By collecting and analyzing 125 recent rumors from six popular fact-checking sites, and their associated 289,202 tweets/retweets generated by 176,362 users, we find that the rumors that are spread by rumor echo chamber members tend to be more viral and quickly propagated than those that are not spread by echo chamber members. We propose the notion of an echo chamber network that represents relations among rumor echo chambers. By identifying the hub rumor echo chambers (in terms of connectivity to other rumor echo chambers) in the echo chamber network, we show that the top 10% of hub rumor echo chambers contribute to propagation of 24% rumors by eliciting more than 36% of retweets, implying that core rumor echo chambers significantly contribute to rumor spreads.
Measurement Framework
To identify and analyze echo chambers in rumor propagation, we developed the data collection system as shown in the figure below, by which we crawled the rumors and their meta information from the six popular online debunking websites: snopes.com, politifact.com, factcheck.org, hoaxslayer.com, truthorfiction.com, and urbanlegends.about.com. Since all the above services did not provide APIs to collect data, we fetched every single web page and extracted rumor-related information including the claim (description of a rumor), veracity (e.g., true, false), category (e.g., politics, health), editor who determines the veracity of the rumor, and description of evidence. The description of rumors (i.e., claims) is delivered to the keyword extractor, which generates a set of words by tokenizing a given claim and removing stopwords. Note that we only considered the claims that include more than three words to avoid collecting trivial tweets/retweets. Finally, the generated set of words for a rumor is forwarded to the Twitter crawler in our system.
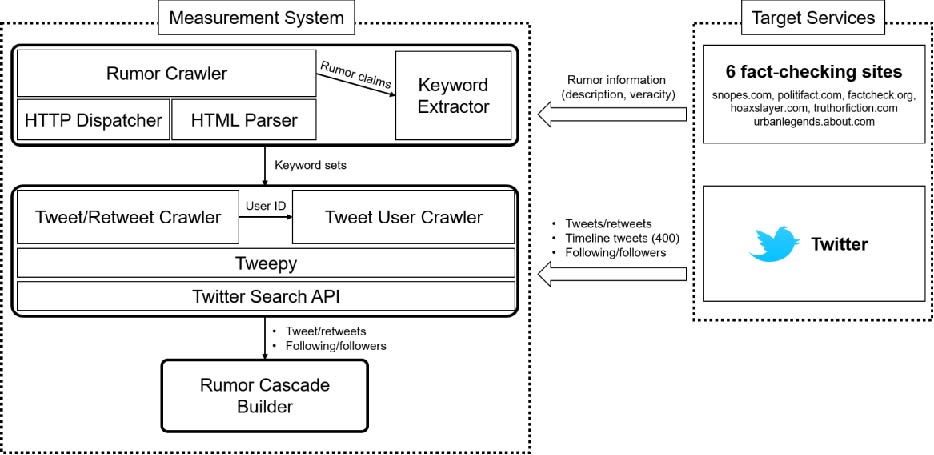 ”
”
The Twitter crawler retrieved the tweets/retweets associated with rumors by using the Tweepy, a Python library for accessing the Twitter Search API. Among the collected tweets/retweets, we filtered out the retweets generated by bot accounts using the machine learning-based algorithm suggested in Davis et. al.. That is, the bot detection model accepts a user ID, gathers information of the user in Twitter, and builds more than 1,000 features including information diffusion patterns, social contacts of an account, inter-tweet time distribution, etc. Using the features and pre-trained model with high performance (AUC: 0.95), we finally identified 15.5% accounts as bots, and their tweets/retweets are removed while building rumor cascades. We also collected the information of users associated with the collected tweets/retweets, including the follower/following information and all the tweets posted on the timeline.
Using the collected tweet/retweets of the crawled rumors, we build rumor cascades, where nodes and edges represent a set of tweet/retweets and retweeting actions, respectively. Since the crawled retweets include only the original tweet information, we infer the retweet path of a tweet by using the original post ID and users’ follower information. That is, for a given original tweet t written by user i, we first extracted a set of retweets whose original tweet is t (denoted as St). We then chose a subset of retweets whose elements (i.e., retweets) are written by i’s followers (denoted as S’t ) which are deemed child retweets of the original tweet. To find retweet paths of the retweets in S’t, we first sorted the retweets in S’t in a chronological order and then inferred retweet paths of each retweet with a similar manner. Note that this approach assumes that users may tend to retweet from earlier tweet/retweets. By recursively computing retweet paths until all tweet/retweets in St found the path, we can finally build a retweet cascade that represents a rumor cascade. Note that we only consider rumor cascades whose sizes are equal to or greater than 100 in our analysis.
Dataset
Collecting rumors and their associated rumor cascades from Jan. 2018 to Oct. 2018 for 10 months, we finally obtain 125 rumors whose veracity is true, false, or mixed, and 37,417 rumor cascades consisting of 289,202 tweets/retweets written by 176,362 users. Note that we keep the terms of use of all target services during the data collection process, and the collected dataset is anonymized. We make the information of the rumors investigated in this paper publicly available as follows. The other datasets analyzed during the current study are available from the corresponding author on reasonable request.
- Rumor Information (29K)
- Each columns are seperated by tab(‘\t’).
- Dataset Schema is written in the first row of the file.
Supplementary Materials
Contact
Daejin Choi (djchoi@inu.ac.kr) Jinyoung Han (jinyounghan@skku.edu)